Architecture technique du projet Envinorma
Il y a quatre composants principaux au projet :
- L’application principale (et son double de pré-prod)
- Un back office
- Un ensemble de tâches de préparation des données, implémentées ici
- Trois buckets de stockages d’objets, pour stocker les AP transformés, les AM transformés et les données ICPE.
Liste des applications
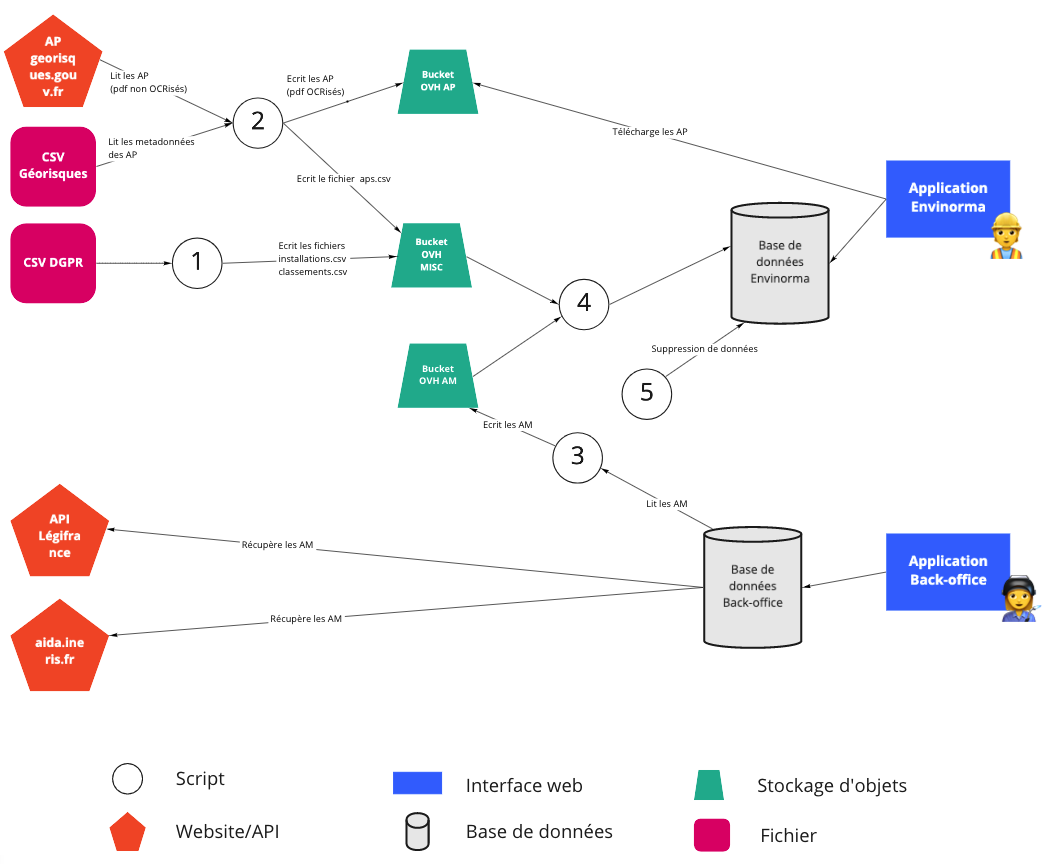
Liste des tâches référencées sur le schéma ci-dessus
- Script python, exécuté manuellement à chaque réception d’un CSV. Transforme les données ICPE (installations et classements) et écrit les fichiers installations_all.csv, classements_all.csv dans le bucket OVH
MISC. (Exécution : environ 2 minutes.) - Script python, exécuté tous les matins à 7h (UTC) sur la machine
data-taskssur OVH. Récupère les métadonnées des AP, OCR les nouveaux AP et écrit le fichier aps_all.csv dans le bucket OVHMISC. (Exécution : environ 1h.) - Script python, intégré au back office. Exécution manuelle sur demande de l’utilisateur du back-office via un bouton. Exporte les AM au format JSON et les écrit dans le bucket OVH
AM. (Exécution : environ 2 minutes.) - Scripts rails. Met à jour les AP, les classements et les installations de la base de donnée Envinorma. La mise à jour des AP est quotidienne et automatique (tâche Heroku scheduler quotidienne à 21h UTC). La mise à jours des installations et des classements est manuelle. (Exécution : environ 2 minutes.)
- Script rails, automatique, tous les jours à 1h du matin (UTC). Supprime tous les utilisateurs qui ne se sont pas connectés depuis plus de 3 mois ainsi que les installations et les prescriptions associées. (Exécution : environ 2 minutes.)
App envinorma
- Actuellement déployée sur Heroku, version payante pour la base de données et la dyno
- Postgres v12.7, 400k lignes, 10 tables, 125 Mo de données, backup hebdomadaire
- App : ruby 2.7.4, rails 6.0.4.
- Toutes les dépendances ruby : https://github.com/Envinorma/envinorma-web/blob/master/Gemfile
- Toutes les dépendances javascript : https://github.com/Envinorma/envinorma-web/blob/master/yarn.lock
- RAM: 512 Mo
- 1 CPU
- Espace disque: 500 Mo
- Pas d’authentification
- https
App envinorma-staging (environnement de pre-prod)
- Actuellement déployée sur Heroku, version gratuite
- Mêmes caractéristiques qu’Envinorma, avec une base de données plus petite
App back-office
- Actuellement déployée sur Heroku, version gratuite
- Postgres v12.7, 2000 lignes, 5 tables, 33Mo de données, backup hebdomadaire
- App : python 3.9, dash 1.21.0
- Liste des dépendances : https://github.com/Envinorma/back-office/blob/main/requirements.txt
- RAM: 512 Mo
- 1 CPU
- Espace disque: 500 Mo
- Authentification simple
- https
Data-tasks (tâches effectuées périodiquement pour préparer la donnée nécessaire au bon fonctionnement des applications)
- Docker (ou Python 3.9)
- Liste des dépendances python : https://github.com/Envinorma/data-tasks/blob/main/requirements.txt
- Package ubuntu dépendants pour l’OCR : ghostscript, icc-profiles-free, liblept5, libxml2, pngquant, python3-pip, tesseract-ocr, tesseract-ocr-fra, zlib1g
Stockage d’objets
- Trois buckets : un pour les AM, un pour les AP et un pour les CSV
- Capacité de l’ordre de 150Go en tout
- Accessible via https, exemple : https://storage.sbg.cloud.ovh.net/v1/AUTH_3287ea227a904f04ad4e8bceb0776108/ap/P/6/9107c345c15a46e681e2a5546dca78d6.pdf
Monitoring
- Sentry pour l’app envinorma
- Google analytics pour l’app envinorma
- Slack pour les data-tasks et le back-office
- Heroku dashboard pour le monitoring des utilisations en RAM/CPU/Disque des deux applications et bases de données